Haven Studios:機械学習を活用した脱出ゲームを試作
画像生成やテキスト生成、視覚言語モデルを併用したポイント&クリック方式のアドベンチャーゲームの作成


AI技術を基にしたテキストゲームは、文章生成が行える言語モデルと同じくらい歴史があり、チャットモデルがストーリーを誘導する形でゲームが進行します。そして、Text-to-Imageモデル(文章から画像を生成する機械学習モデル)の進化により、文字だけでなく、イラストを通じてシナリオが描けるようになりました。しかし、こういった体験は基本的にテキストベースで展開されるため、イラストとインタラクト(プレイヤーがゲーム内で特定の動作を行なうこと)する方法や、プレイヤーの行動にペナルティを課すような制約は設けられていませんでした。
従来のポイント&クリック方式のアドベンチャーゲーム(あるいは隠しオブジェクトゲーム)を再現するには何が必要か、また、これらを実現できる言語モデルは存在するのか、といったテーマを検証するため、私たちはブラウザゲームのプロトタイプを作成しました。このプロトタイプは、プレイヤーの入力内容に応じてさまざまなアイテムが配置された密室を作成し、短い脱出ゲーム方式のパズルを生成します。そして、アイテムをクリックすることで、プレイヤーはアイテムとインタラクトすることが可能です。
今回は、私たちの実験的な取り組みの詳細や、機械学習モデルを活用した方法やプロセスなどをご紹介します。
ゲームの概要
まず、プレイヤーが「城」や「海賊船」といった短いフレーズを入力すると、室内とストーリーの目的が生成されます。

プレイヤーはアイテムをタップしてインベントリに取り込み、それらをドラッグしてパズルを解き、密室からの脱出を目指します。

ひとつの部屋の脱出に成功すると、同じテーマで作られた新たな部屋に進むため、プレイヤーは無限に遊び続けることができます。
最初の部屋とインタラクティブなパズルが生成されるのに、およそ1分かかります。その間に、プレイヤーがリクエストしたテーマに基づき、大規模言語モデル(LLM)を搭載したゲームキャラクターが、会話ツリー(複数の選択肢からなる会話の分岐システム)を使ってプレイヤーとの会話を開始します。このプレイヤーとキャラクターのやり取りは、この後、部屋に配置されるアイテムの説明文にも影響するため、生成の待機時間もメインのゲーム体験と結びつくように設計されています。
制約
私たちは、専門的なエンジニアリングの知識やリソースを必要とせず、エンドユーザーへの要求もなく、一定の規模で展開できるゲームを目指していました。そのため、webアプリケーションのサーバーを実行する際に呼び出すAIモデルは、外部の環境でホストされているものを導入することにしました。その結果、Anthropic社の次世代生成AIモデル「Claude」と、最先端のパフォーマンス、コスト、スピードのバランスが取れたモデルホスティングサービスの視覚および画像言語モデルの活用を決めました。
イラストの生成
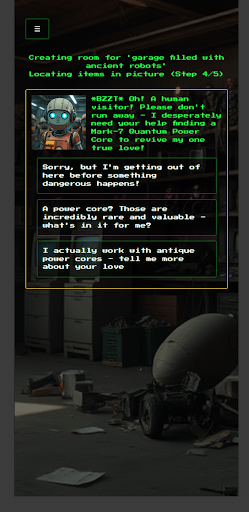
このゲームで必要な入力は「城」や「海賊船」といった短いフレーズのみです。私たちの最初の課題は、入力されたテキストを基に、面白い脱出ゲームのベースとなる画像を生成することでした。画像生成には、ひとつのイラストに複数の被写体を描写する機能を搭載したFLUX.1を利用しました。また、面白いパズルを作るには、画像生成パイプライン(下図)により多くの情報を与え、たくさんの物が散らかった部屋を生成する必要があることがわかりました。これを達成するため、LLMが入力された短いフレーズを拡張し、プレイヤーの視点や照明、部屋を埋めつくすアイテムなどを提案し、リストアップします。
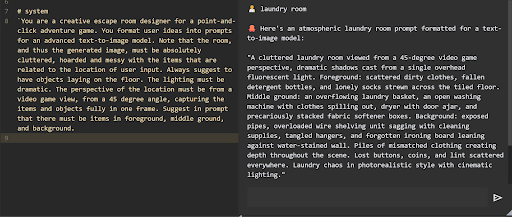
この方法では、LLMが提案したアイテムのすべてを実際のゲームに取り入れる必要はないということが重要なポイントです。そして、この段階で生成された画像と、その中の検出可能なオブジェクトがパズルの基礎を作ります。
セマンティックセグメンテーション
次のステップは、パズルを構成するオブジェクトの特定です。このためには、非常に優れたセマンティックセグメンテーション(画像のピクセル一つひとつに対して、何が写っているかといった、ラベルやカテゴリー付けすること)が必要になります。このタスクに対して、まずは既存のモデルやパイプラインをいくつか試してみたものの、従来のアプローチでは必要なアイテムの識別やセグメンテーションの精度が得られませんでした。検出されるオブジェクトは、ゲーム内でプレイヤーがインタラクト可能なアイテムであるため、ラベル付けが不十分なアイテムはプレイヤーの没入感を損なってしまいます。

最終的には、画像内のアイテムを特定するためにClaude、それらのアイテムのバウンディングボックスを検出するためにFlorence 2、ボックスをセグメントとして切り出すためにSAM(Segment Anything Model)を活用することにしました。これらのモデルを組み合わせることで、オブジェクト識別の精度が向上し、プロジェクトが終わる頃には、プレイヤーからオブジェクトの誤認識について指摘されることはほとんどなくなりました。
このアプローチはRAM-Grounded-SAM(Recognize Anything ModelとGrounded-Segment Anything Modelの強みを組み合わせたAIモデル)から着想を得ています。現代の視覚学習モデルが多数の異なるオブジェクトを識別でき、Florence 2が非常に優れた視覚言語モデルであることも、このアプローチの利点のひとつでした。
パズルの作成
オブジェクトでセグメント化された画像が生成されると、次にオブジェクトのリストをLLMに提供し、パズルを構築します。パズルの構造は比較的単純です。ひとつのアイテムを別のアイテムに対して使用することで、アイテムのひとつを更新、新しいアイテムを合成、または最終脱出のために使用できます。例えば、以下のようにアイテムを組み合わせることが可能です。
椅子の脚+暖炉=燃え盛るトーチ(椅子の脚とインベントリを交換)
ドライバー+机=隠された鍵
隠し鍵+ドア=脱出
Claudeは、私たちの予想以上に論理的で矛盾のないインタラクションを生成することができましたが、下記のような難解かつ不自然なインタラクションが生成される場合もありました。
紙+水=鍵の型
アクションフィギュア+ランプ=鍵穴にロウを流し込む
バイク+天井の換気口=脱出
画像編集
プレイヤーが謎解きを進めるに合わせて、部屋自体もプレイヤーのインタラクションを反映し、更新されなければなりません。そのため、私たちはインペインティング、または生成塗りつぶし(画像の一部を修正または別のものに置き換える機能)を基にした画像編集の手法を取り入れました。
まず、プレイヤーがゲーム画面でアイテムを「掴んだ」とき、それらは部屋の中から取り除かれる必要があります。最初に生成された画像にはアイテムがすでに配置されているため、プロセスをさかのぼり、掴んだアイテムを切り取ってから、その隙間を塗りつぶすことで、部屋からアイテムを取り除くことができます。私たちはまず、Stable Diffusion 1.5やXLといった前世代の画像生成AIモデルを試してみましたが、隙間の細部まで補正するには最新のFLUX Devモデルを活用する必要があることがわかりました。Devは、取り除かれたアイテムの後ろに敷かれたラグの模様までも正確に補正させることができたのです。



私たちは、パズルの最中に発見または合成されたアイテムのインベントリアイコンを生成するためにも、インペインティングを活用しました。横に並んだ2コマの画像を生成し、左は元のアイテムの参照画像として固定され、右はインペインティングで更新されたアイテムを描写します(たとえば、「魔法のオーブ」から「光るオーブ」への変化など)。
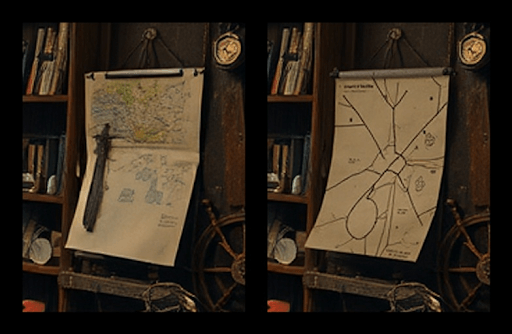
最後に、ゲーム内のアイテムの見た目がパズルの内容と一致するよう調整するため、より本格的な画像編集機能が必要でした。たとえば、機械装置が作動して光線が発せられている様子を描写する場合など、変化の内容を表した画像と説明をベースに、元のオブジェクトとそれに対して起きた変化を描写した新たな画像を生成できるような機能です。
これらに特化した現行または最新のモデルやパイプラインは存在していたものの、少なくともこのプロジェクトが進行していた時点では、「安価かつ外部でホストされているモデルAPIを使用する」という自分達に課した制約により、それらを利用することはできませんでした。代わりに、私たちはインベントリ画像の作成プロセスと同じような2コマの生成方式を用い、左のイラストをアイテムの元々の見た目として参照し、右のイラストにインペインティングで更新されたアイテムを生成する方法を活用しました。
バックストーリー
前述したように、入力されたテーマに沿ったキャラクターとの会話は、最初の部屋の生成時間(約1分)を埋めることと、ゲーム本編におけるアイテム説明にアレンジを加える、というふたつの目的を果たしています。ふたつ目の目的は、当初はあくまでも実用的な理由から実装したものでしたが、結果的にゲーム体験に大きな影響を与えました。パズルジェネレーターは、アイテムの短い説明と、パズルを解く手順のヒントを生成します。そして、キャラクターとのやり取りを基にしたバックストーリーをアイテムの説明やヒントに加えることで、ゲームの没入感を高めることができました。
前:マホガニーの椅子
後: ああ、それはミドルトン様が大事になさっていた椅子です。海外から輸入したマホガニーのフレームにベネチアンシルクのクッションをあしらっていて…
興味深い会話や台詞を構成するため、私たちは「ドラマの根本には葛藤があり、ドラマ上のすべてのシーンは、正反対な人物同士の対立から始まる」という古くからある脚本術を参考にしました。
私たちの構築したシステムは、ゲーム内のすべてのインタラクションをユニークな台詞や説明で補うことができ、この点が従来のゲームとは異なる要素のひとつだと思います。古典的なアドベンチャーゲームでは、「YにXは使えない」と表示されるか、プレイヤーのインタラクションを防ぐような手段が用いられます。しかし、このシステムを活用すれば、さまざまな組み合わせのマトリックスをLLMに送ることで、バックストーリーのようなディテールを補完することが可能となります。
オーケストレーション
私たちの構築したシステムには、互いに依存する異なる生成タスクが複数含まれています。たとえば、部屋の画像生成はアイテム識別の入力につながり、それがさらにパズルの生成につながります。そして、これらはすべてオンラインサービスの中でスケールアップし、結果はデータベースに保存され、エラーが発生すれば再試行されるように設計されています。
これらのプロセスを管理するため私たちはさまざまなタスクを、メインのモデルクラスの入力フィールドと出力フィールドに付随する独立した関数に分割しました。小さなユーティリティ関数は、特定のオブジェクトに対してどのタスクを(再)実行する必要があるかをチェックします。この関数はタイミング情報も記録するため、生成プロセスにおけるボトルネックや並列処理が実行可能なステップが確認できる、下記のようなウォーターフォールチャートを作成しました。
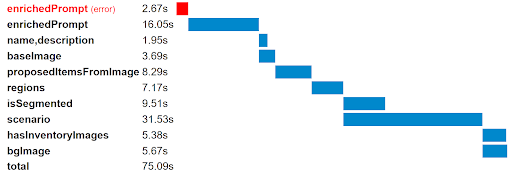
このプロセスにおいては、小さなユーティリティ関数が活用できたため、既存のソリューションにリソースを費やす必要はありませんでした。しかし、タスクやステートマネジメントが行えるソリューションの実装は、複数のパイプラインを管理する機械学習がベースのアプリケーションにとって効果的です。オフラインデータを処理する場合のワークフローオーケストレーションと似たようなフレームワークが、オンラインデータを処理する場合も活用でき、アプリケーションスタックにより統合されれば、プロセスをさらに効率化できると思います。
最後に
本プロジェクトを終え、私たちはいくつかの貴重な学びを得ました。
- AIを活用した、プレイヤーが継続的に楽しめるインタラクティブなグラフィックゲームの作成は可能
- 世界観の構築は生成機械学習にとって最も簡単なタスクであると同時に、今回作成したようなアプリケーションにとっては非常に重要な要素で、魅力のひとつである
- 機械学習を活用したアプリケーションには不確定要素が多いため、効果的なタスク管理やステートマネジメントのためのソリューションが必要
私たちの取り組みについてここまで読んでいただき、ありがとうございます。これからも引き続き、AIや機械学習を活用した実験的なゲームの開発プロセスについて紹介できることを楽しみにしています!

Chloe Cho:Haven Studioにおける機械学習チームのゲームデザイナー。大規模言語モデルを活用したゲームの開発に携わっている。ラピッドプロトタイプだけでなく、クリエイティブな観点からのソリューションなどをチームに提案している。

Evan Jones:Haven Studiosにおける機械学習エンジニア。画期的な方法で機械学習モデルを組み合わせ、機械学習を活用したゲームを制作している。
関連記事



原文はこちら