Fully Automated Kubernetes Operations
A New Era in Kubernetes Management
PlayStation Network (PSN) operates through a vast array of services, spread across multiple teams and global locations. To bring alignment and consistency, we adopted Kubernetes as a unified platform. However, managing such diversity—both technical and organizational—put immense pressure on the platform and the way we managed it. The challenge was clear: we needed a more efficient approach.
Now, imagine a world where your Kubernetes clusters manage themselves. No more late-night crisis management, no manual updates, and no firefighting. What might sound like a distant fantasy is the new reality at PSN Platform. In the fast-paced, cloud-native world, Kubernetes quickly became the standard for container orchestration, offering immense power but at a cost: complexity. Traditionally, managing Kubernetes clusters demanded high manual intervention and deep expertise.
But what if we could turn that complexity into simplicity? What if the entire process could be automated, freeing up developers and SREs to focus on what really drives value—innovation and growth? That’s exactly the transformation we’ve achieved. Welcome to the new era of fully automated Kubernetes operations at PSN, where teams can now focus on what matters most while the platform takes care of itself.
The Challenge: Wrestling with Complexity
Our journey began with a simple yet profound question: How can we make Kubernetes easier to manage while maintaining the flexibility and power that make it essential? Like many organizations, we faced numerous challenges:
- Inconsistent Infrastructure as Code (IaC) Definitions: Different teams used different tools, leading to discrepancies in cluster configurations and resource allocations. This lack of consistency caused environments to fall out of sync, leading to instability and unpredictability.
- Manual Processes: Setting up new Kubernetes clusters was a manual, multi-step process. Configuring VPCs, subnets, IAM roles—each step required manual effort, leading to inefficiencies, errors, and delays. Scaling resources was labor-intensive, and keeping everything up-to-date required constant manual intervention.
- Limited Automation: Repetitive tasks consumed valuable engineering time, bogging down our operations. Manual scaling, backups, and security patches were the norm, leaving our infrastructure vulnerable and our teams overworked.
- Operational Complexity: Managing over 50 Kubernetes clusters, each with more than 50+ add-ons, became increasingly complex. From networking and IAM roles to performance optimization and security, the manual effort was immense.
The Root of the Problem: Why Complexity Ruled
As we dug deeper, we uncovered the root causes of our challenges:
- Customization Needs: Geographical dispersed departments had different network and security designs that were built to standards and practices developed in isolation. This led to different network designs and approaches on how and where security controls were deployed.
- Multi-Team Involvement: Managing these clusters required extensive coordination among teams—network, security, observability. Each change needed approvals, often leading to bottlenecks and miscommunications.
- Manual Validation: Manual processes introduced errors and delayed deployments. Without automated checks, standards varied, leading to inconsistencies and potential vulnerabilities.
- Lack of Unified Processes: Without standardized tools and practices, each team followed its own methods, causing confusion and inefficiency. Onboarding new team members was slow, and resolving conflicts took time.
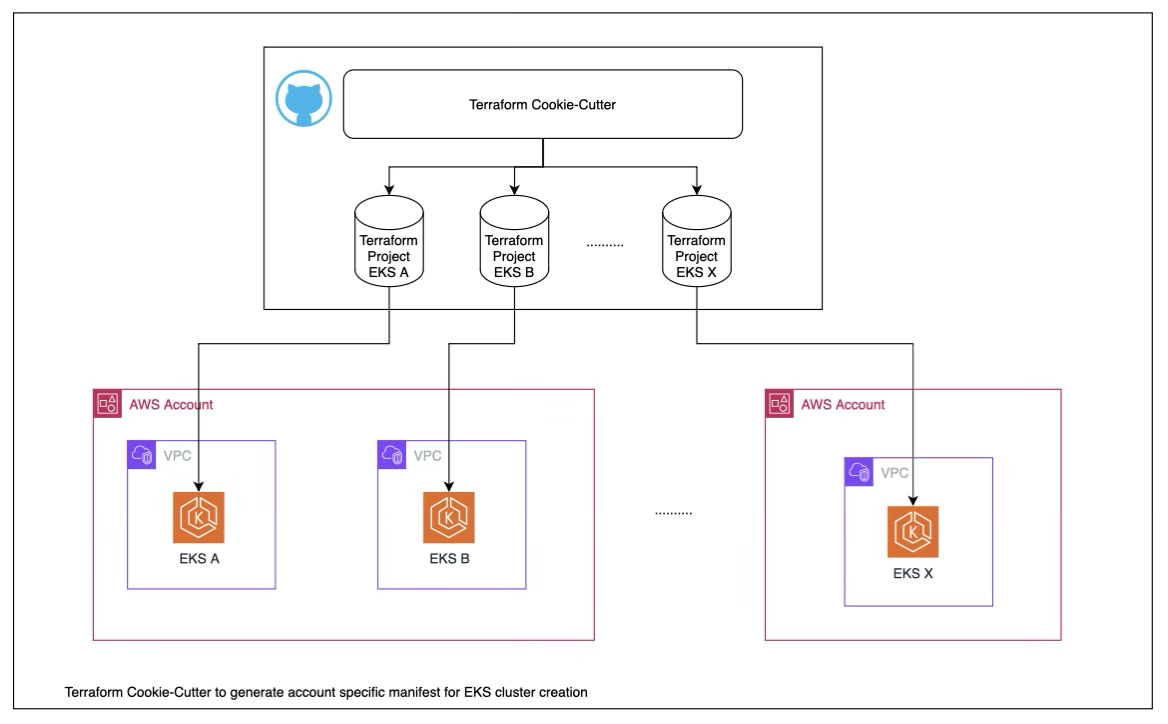
The Turning Point: Embracing Standards and Automation
Faced with these complexities, we knew a fundamental shift was needed. The answer lay in defining standard and embracing automation—not just as a tool, but as a new operational philosophy.
- Standardizing Tools and Practices: We selected Terraform as our unified IaC tool, allowing us to standardize our environments and reduce surprises during deployments. By adopting a cookie-cutter process, we streamlined cluster creation, making it faster and more consistent across the organization. Regulatory standards were addressed by deploying policy engines that enforced security standards ensuring that our Kubernetes clusters met PSN Security Policy and met regulatory requirements such as PCI and SOX.
- Automating IaC and Monitoring: We automated the creation and configuration of Kubernetes clusters using Terraform and custom scripts integrated with a GitOps pipeline. Monitoring tools were implemented to detect and alert on issues proactively, reducing the need for manual intervention. This included monitoring cluster add-ons, worker nodes, and subnet IP usage, allowing auto-scaling based on traffic patterns.
- Self-Service Processes: To empower our teams, we introduced self-service tools that allowed them to handle common tasks independently. Teams could now create IAM roles, container image repositories, and more without waiting for approvals, accelerating the onboarding process.
- Automated Validation: We automated the validation of our IaC configurations and Kubernetes cluster setups. Using tools like Terratest and Sonobuoy, we ensured that our infrastructure was provisioned correctly and that critical add-ons were configured properly. Monitoring and logging configurations were also validated to ensure they meet our standards for ongoing management.
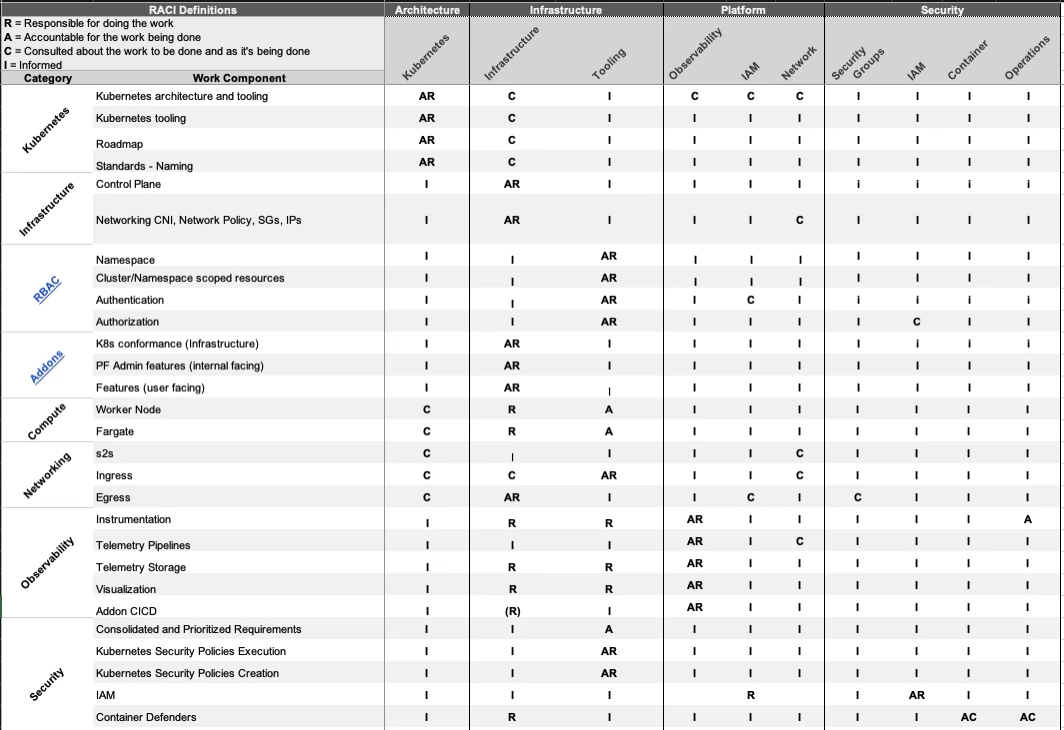
- Fostering Team Collaboration: We established a RACI (Responsible, Accountable, Consulted, and Informed) structure to set clear expectations about each team’s role in the cluster creation and validation process. This approach removed the confusion of what needed approvals, accelerating the delivery of clusters from weeks to hours.
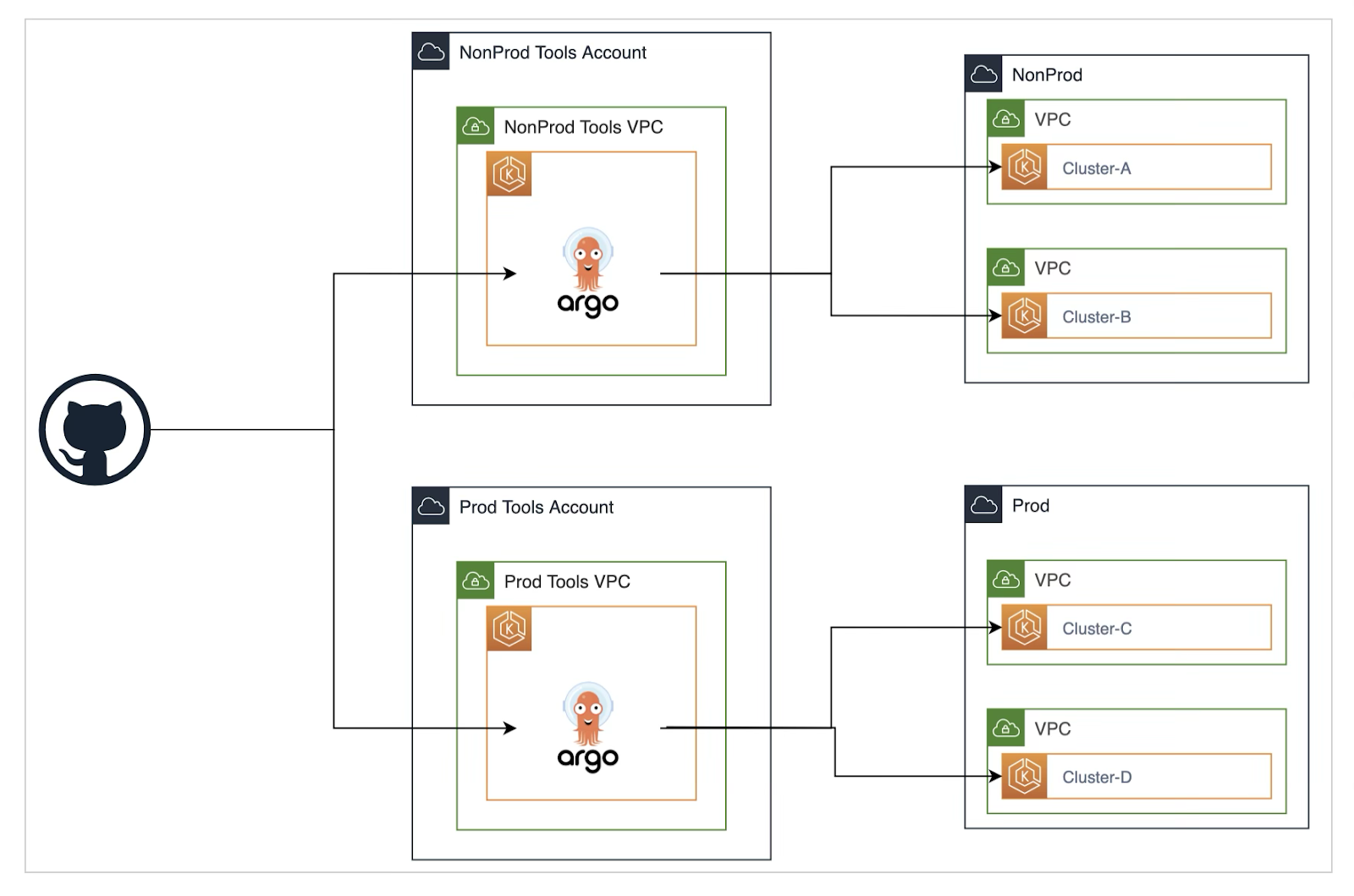
Conquering the Chaos of Kubernetes Add-Ons
The Initial Setup: Helm and Terraform
When we first ventured into managing Kubernetes add-ons, we chose Helm for most configurations, complemented by Terraform modules for each component. This approach provided consistency across our growing fleet of Kubernetes clusters, seamlessly fitting into our deployment workflow. Initially, everything worked like a charm, and we were confident in our setup.
The Growing Pains: Emerging Issues
However, as our clusters expanded—reaching over 50 clusters and supporting more than 50+ add-ons—we began encountering challenges that threatened to disrupt our operations:
- Operational Gaps: With the increase in clusters, we started facing PR conflicts and difficulties in managing dependencies among the add-ons. What once felt manageable now required constant attention.
- Intermittent Outages: Critical add-ons like CoreDNS and VPC CNI began experiencing outages, often accompanied by vague, generic error messages that made debugging a frustrating process.
- Team Ownership: The management of cluster add-ons was distributed across various teams—security, observability, and costing, to name a few. This division of responsibilities made it clear that we needed a more sustainable and coordinated deployment strategy.
A Path Forward: Identifying the Requirements
To address these challenges, we outlined key requirements for a robust add-on management approach:
- Distributed Deployment: We needed a system that could efficiently roll out add-ons across multiple clusters without causing disruptions.
- Support for Variability: The solution had to accommodate clusters with different configurations, ensuring flexibility without compromising reliability.
- Failure Reduction: Minimizing the impact of failures while maintaining deployment agility became a priority, as we aimed to reduce the risks associated with scaling.
The Solution: Embracing ArgoCD
To meet these demands, we turned to ArgoCD, which provided a declarative, automated approach to managing Kubernetes add-ons:
- Declarative Deployment: With ArgoCD, we began deploying Helm charts in a declarative manner, which not only streamlined the process but also provided clear visibility into the health of our Kubernetes workloads.
- Application Set Controller: By using the ArgoCD application set controller, we managed multiple clusters with a single manifest, ensuring consistency across the board.
- Distributed Approach: We implemented dedicated ArgoCD instances and application sets for different teams within the organization. This approach reduced conflicts, kept workloads in sync with their source manifests, and allowed for more granular control.
- Independent Operation: Each team was now empowered to manage their add-ons independently, with clear ownership and accountability. This not only improved efficiency but also reduced dependencies, allowing for faster, more reliable deployments.
ArgoCD Incident: Lessons in Managing Critical Cluster Add-ons
- As part of our ongoing efforts to optimize cluster operations and enhance the reliability of our infrastructure, we recently faced a significant incident involving ArgoCD and critical add-ons like CoreDNS and VPC-CNI. This event affected the entire cluster environment due to a cyclic dependency that emerged during routine updates. Both the tools cluster and service clusters experienced issues when these vital add-ons were inadvertently removed during the update process.
- The situation was further complicated by the fact that we had been managing multiple clusters through a single manifest as was one of our original goals to reduce complexity. However, when that manifest was updated incorrectly, it had a much larger blast radius and affected multiple clusters, leading to widespread disruption. After conducting a detailed review, we identified that the root cause lay in a few design decisions made early in the implementation phase.
Specifically, managing critical cluster add-ons such as CoreDNS and VPC-CNI through ArgoCD, and consolidating multiple clusters into a single manifest, introduced practical issues that ultimately compromised the stability of our system.
Post-Incident Improvements
- In response to these challenges, we took immediate action to improve our infrastructure’s resilience. First, we decided to migrate the management of critical add-ons, like CoreDNS and VPC-CNI, from ArgoCD to Terraform. By tying these critical components more closely to our cluster Infrastructure-as-Code (IaC) operations, we established a more stable and reliable environment. This migration was executed seamlessly, with Terraform taking control of the existing resources without causing any downtime for applications.
- In addition, we split the ArgoCD add-on manifests to manage each cluster independently. This approach allows for more granular control and prevents errors in one cluster from cascading to others. To avoid the overhead of maintaining duplicate manifests for multiple clusters, we implemented an automated progressive deployment framework. This ensures smooth and error-free add-on management across all clusters, while still harnessing the power of ArgoCD for continuous delivery.
- Thanks to these improvements, we were able to perform the migration across all clusters without any impact on application infrastructure, achieving a more reliable and robust operational environment.
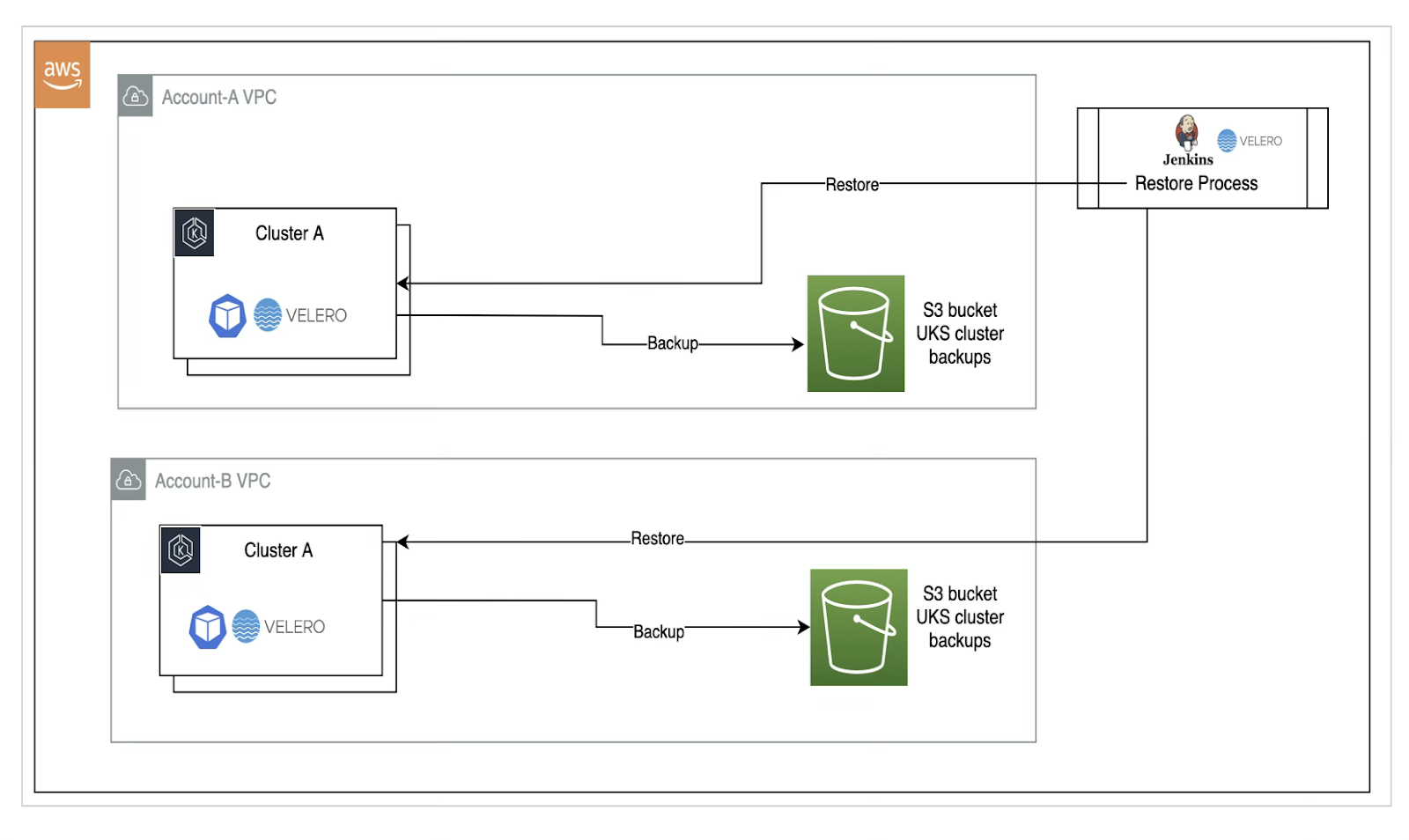
Defining Our Disaster Recovery Plan
Additionally, we also considered and implemented our disaster recovery plan to enhance the effectiveness of our backup strategy, and we set clear objectives to guide the process:
- Recovery Time Objective (RTO): We defined the maximum acceptable downtime based on business requirements and SLAs, ensuring that our disaster recovery plan aligns with our operational needs.
- Recovery Point Objective (RPO): By determining the maximum acceptable data loss, we guided our backup frequency, balancing protection with resource efficiency.
Reaping the Rewards: The Benefits of Automation
Our journey to a fully automated Kubernetes platform has yielded remarkable results:
- Consistent IaC and Efficiency: By selecting Terraform as our unified IaC tool, we standardized environments, reducing cluster creation issues considerably low. A cookie-cutter approach cut cluster creation time by 90% i.e from 2 -3 weeks to just 4 – 5 hours, improving consistency across the organization. Automated validation improved IaC accuracy, reducing misconfigurations considerably.
- Scalability and Flexibility: We leveraged Kubernetes’ native auto-scaling features to handle varying traffic loads, maintaining performance and user experience. External metrics through KEDA (Kubernetes Event-driven Autoscaling) allowed us to scale service pods automatically based on demand. Scalability has been improved drastically by eliminating manual intervention by engineers to scale-up service pods based on resource metrics, which in-turn scale up worker nodes automatically to schedule the pods.
- Enhanced Security and Compliance: Automated container scanning and policy enforcement tools like Kyverno helped us maintain continuous compliance with security and network standards. By automating the process, we reduced the RTO by 90% by ensuring the recovery of the platform from backup is available after any disaster.
- Increased Developer Productivity: The faster provisioning of Kubernetes Jenkins agents enabled quicker deployments and more frequent releases. Spinning up in seconds, significantly faster than EC2 agents, Kubernetes agents reduced deployment times by 70%.
The Future: Continuing the Journey
As we look to the future, we remain committed to refining and expanding our automation capabilities. Our next steps include integrating more advanced scale ups, enhancing our disaster recovery strategies, and exploring Service Mesh on Kubernetes for even greater efficiency and cost savings.
Enabling Service mesh using Isitio to provide application capabilities like mTLS authentication, encryption, policy controls, observability, and advanced traffic management without any code change by developers. Establishing a multi-cluster environment to ensure the distributed systems are resilient while staying connected and protected.
Karpenter, Kubernetes native cluster autoscaler with advanced and highly efficient worker node manager. Karpenter simplifies Kubernetes infrastructure by provisioning right sized nodes at the right time using the most cost effective worker node ec2 instances with fully automated life-cycle management. After multi-month of evaluation, rollout has been initiated across our Kubernetes platform to modernize the workload management.
AWS Pod Identity, a new way of managing application IAM credentials in Kubernetes. An evolution from IRSA, Pod identity simplifies IAM permission management for applications in Kubernetes clusters by removing the OIDC limitations when large numbers of service on-boarding in our platform by shifting to a unified trust policy model with granular access control.
The journey to fully automated Kubernetes operations is ongoing, but our successes so far have proven that automation is not just a luxury—it’s a necessity for scaling and sustaining modern cloud-native environments. We’re excited to continue pushing the boundaries of what’s possible. We invite you to join us on this journey to operational excellence and make PlayStation the best place to work.