Haven Studios: Experimenting with ML-driven Escape Room Games
Using image generation, text generation, and vision language models together to create point-and-click adventures


AI-driven text games are as old as language models that can string sentences together. You can just ask a chat model to lead you through a story. The addition of text-to-image models allowed these scenarios to be illustrated. What these experiences lack, however, is the ability to interact with the imagery and hard checks on your actions. They are fundamentally a textual conversation where, more or less, anything goes.
What would it take to replicate the old point-and-click adventure games (or a hidden object game)? Are the model capabilities there yet? To explore this, we created a browser game prototype that creates a scene with objects in response to prompts from the player and makes a short escape room puzzle out of it. The items are clickable and the scene responds to item interactions.
In this post, we’ll give an overview of the experience then dive into how we combined ML models and strategies to realize it.
The Game
After the player enters a short phrase like “castle” or “pirate ship”, the system generates an interior scene and story goal.

The player taps on items, acquiring them to their inventory, and drags them together to solve steps of the puzzle eventually leading to an escape.

After solving one scene, the game prompts the player to continue with another one created in the same theme, and the player can keep on in this way indefinitely.
It takes about a minute to generate the initial scene and interactive puzzle. During that time, an LLM-powered character in the requested theme starts a conversation with the player using a dialogue tree. As a final step, we use the player’s interaction with the character to flavor the item text in the generated scene, tying this preshow into the main experience.
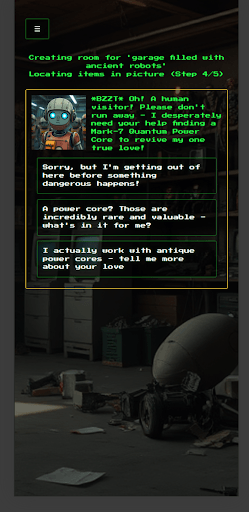
Constraints
Our goal was to build something we could conceivably deploy at scale, without specialized engineering effort and investment, and without any requirements on the end user. For these reasons, we limited ourselves to third-party hosted AI models, which our web app server would invoke at runtime. We settled on Anthropic Claude and a suite of vision and image models from a model hosting service which balanced state-of-the-art performance with cost and speed.
Generating the Scene Image
As mentioned above, the sole input is a short phrase like “castle” or “pirate ship”. Our first challenge was to generate an image that would form the basis for an interesting escape room puzzle. We used FLUX.1 for image generation, leveraging its ability to compose multiple features in a scene. We found that to make interesting puzzles, we needed to start with cluttered rooms, giving the puzzle pipeline (below) enough material to work with. To do this, our LLM expands the short phrase, adding a preferred viewpoint and lighting before listing a multitude of items to fill up the scene.
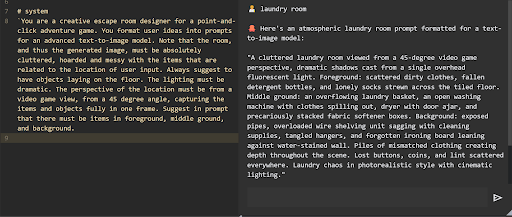
Importantly, our approach doesn’t require that all or even most of the items suggested by the LLM actually make it into the scene. From this point on, the generated image and the detectable objects in it form the basis of the puzzle.
Semantic Segmentation
The next task is to identify objects from which to build a puzzle. This amounts to: we need really good semantic segmentation. While we experimented with existing models or pipelines for this task, we didn’t find that off-the-shelf approaches gave the item identification or segmentation accuracy we needed. These detected objects become the interactable items in the game, and poorly labeled items take the player out of the experience.

Ultimately, we settled on a pipeline of Claude for identifying candidate items in the image, Florence 2 for identifying bounding boxes for as many candidates as possible, and SAM for reducing boxes to segments. Anecdotally, this gave us quite good object identification; by the end of the project, players rarely remarked on misidentified objects.
This approach was inspired by, and is analogous to, RAM-Grounded-SAM. What seems to give our approach the edge is that modern VLMs can pick out a large number of distinct objects in a scene, and Florence 2 is just an exceptional quality vision model.
Making Puzzles
Once we have a scene segmented with objects, we provide the list of objects to the LLM to build a puzzle. The structure of the puzzle is relatively simple: each step is using one item on a different item to either update one of the items, a new item, or a final escape. For example:
chair leg + fireplace = flaming torch (replacing chair leg)
screwdriver + desk = hidden key
hidden key + door = escape
Somewhat surprisingly, Claude consistently produced a valid chain of interactions. That said, we occasionally had issues with the reasonableness of the puzzles – with unintuitive, strained interactions:
Paper + water = mold for key
Action figure + lamp = wax-pour-over for the keyhole
Motorcycle + ceiling vent = escape
Image Editing
As the player progresses through the puzzle, the scene should update to reflect their interactions. To accomplish this, we employed a few image editing strategies rooted in inpainting (or generative fill).
First, as the player “takes” items from the scene, they should visually disappear. Since the initially generated image is populated with items, we do this by working backwards, cutting out items that will be removable in the puzzle and inpainting the gaps. We initially tried a previous generation model like Stable Diffusion 1.5 or XL for this but found even here that FLUX Dev was required to adequately fill in details. For instance, Dev was able to accurately complete the pattern on a rug behind a removable item.



We used inpainting in a different way to generate inventory icons for items found/created during puzzles. We generate a two-frame image with the left fixed as a reference image from the original scene and the right image as the filled-in, new item, for instance, a “glowing orb” item derived from a “magical orb”.
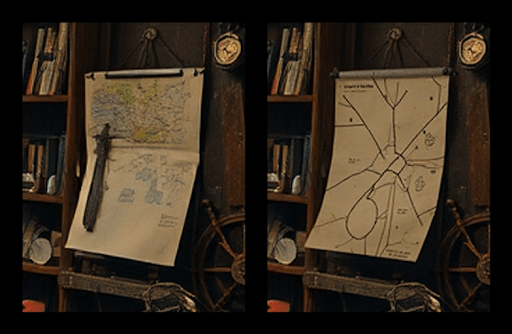
Finally, we needed true image editing to adjust the appearance of items in the scene where it suits the puzzle. For instance, a mechanical device might emit a beam of light when activated. Ideally, we would want a pipeline that could take an image and a textual description of the change and return a new image that is consistent with both the original and the requested change. And while there are current and upcoming models and pipelines dedicated to this, they were ruled out by our constraint of using economical, hosted model APIs, at least at the time this project was written. Instead, we used a similar two-frame approach as the inventory image creation task, with the original appearance of the item as the left image and the updated version inpainted as the right image.
Lore
As described above, we generate a dialogue tree conversation with a character in the theme of the scene, which serves the dual purpose of filling the initial generation time (about a minute) and providing flavor for the item descriptions in the main game. That second purpose started as a matter of convenience but it had a big impact on the experience. The puzzle generator outputs short, functional descriptions of items and hints of puzzle steps; this “lorification” from the character dialogue transforms that into a world the player can inhabit.
Before: A mahogany chair
After: Ah, that’s Master Middleton’s prized calculation chair – imported mahogany frame with Venetian silk cushioning…
To set up an interesting dialogue, we followed an old screenwriting rule that every scene should have conflict, with characters having opposing goals.
The system fills every interaction in the game with unique dialogue and descriptions, and this is one area that sets it apart somewhat from traditional games. A classic adventure game might say “you can’t use X on Y” or just prevent interaction, where we can send a matrix of possible combinations to an LLM to fill out.
Orchestration
The preceding sections make it clear that this system involved a number of different generation tasks with dependencies on one another. For instance, the scene image generation provides the input for item detection, which is the input for puzzle creation. And all of this was designed to scale up in an online service, saving results in a database, retrying on errors.
To manage this, we split up the various tasks into independent functions attached to input and output fields on our main model class. A small utility function checks which tasks need to be (re)run on a given object. It also logs timing information, which allowed us to make waterfall charts highlighting the bottlenecks and opportunities for parallelism in the generation process:
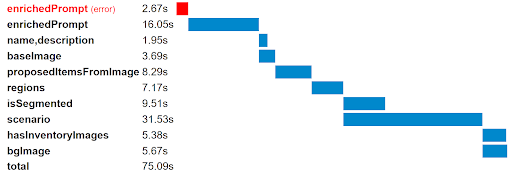
It was not worth investing in an existing solution here (a small utility function was sufficient), but it does seem like ML-powered apps that coordinate multiple pipelines will benefit from a nice solution for task and state management. It is reminiscent of workflow orchestration frameworks for offline data processing, but for online processing in this case and perhaps more integrated into the application stack.
Conclusion
We concluded this project with a number of takeaways:
- It is now possible to create interactive graphical games powered by AI that are consistently fun
- Worldbuilding, although in some ways the easiest task for generative ML, is still very important and a big draw for this type of application
- As ML-powered applications involve more moving parts, a solution will be needed for effective task and state management
Thanks for taking the time to read about our work and we hope to share more AI/ML game experiments in the future!

Chloe Cho is a game designer on the ML team at Haven studios who designs games powered by LLMs. She works with the team to not only rapid prototype, but also suggest solutions from a creative perspective.

Evan Jones is an ML engineer at Haven Studios who makes ML game visions a reality. He smooshes together ML models in sometimes strange and unexpected ways
Related Posts


